

Welcome to the world of data-driven organizations where it is crucial to have a well governed repository to efficiently store and manage your valuable data. But with so many options available, finding the right approach can be overwhelming.
When it comes to architecting an analytics-supporting data repository, there are two main approaches to consider. The first is the traditional three-tier relational approach, known as an Analytical Data Mart (ADM). The second is the popular Data Lake approach.
Each approach comes with its own unique advantages and disadvantages, allowing you to tailor your data storage solution to meet the specific requirements of your organization. In some more advanced organizations ADM and Data Lakes may even complement each other rather than be competing ideas or architectures. For this article we are focusing more on how they are similar or different rather than how they might work together (e.g., build an ADM on top of a Data Lake).
Below we have outlined the advantages and disadvantages of both approaches to help you make an informed decision.
ADM – Advantages and Disadvantages
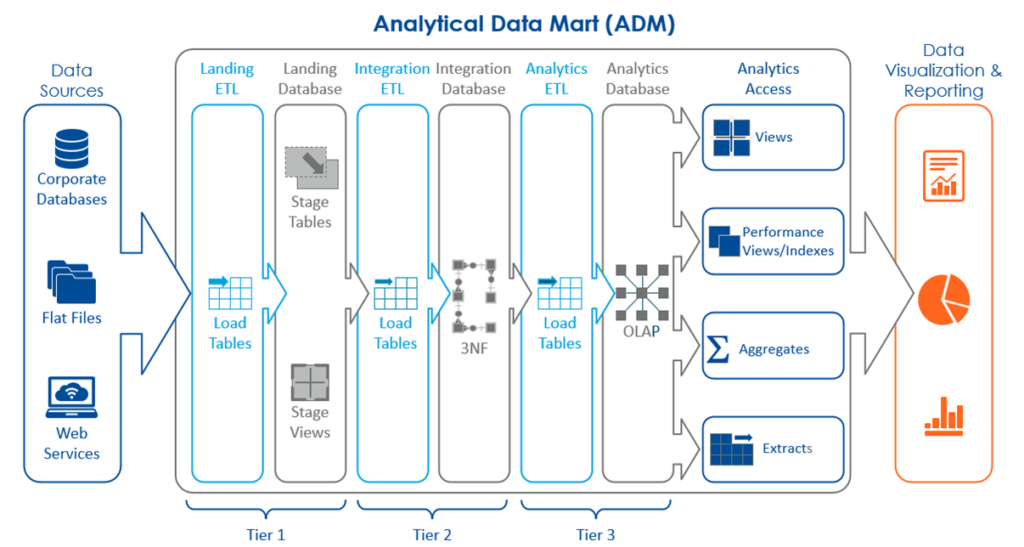
An Analytical Data Mart is a subset of a data warehouse that is designed for a specific business function or line of business. It contains a pre-defined set of data that is organized according to the needs of the business function. Analytical Data Marts are ideal for organizations that need to store and analyze structured data related to a specific function or process, such as finance, marketing, or sales. They offer fast query performance and easy data access for business users, making them an excellent choice for organizations with limited resources and specific data needs.
A structured ADM approach generally requires more initial work to connect to data sources, extract data from the source, restructure and prepare it, then store it in structured storage, such as a relational database (i.e., SQL Server, MySQL, etc.). This type of approach offers more control over the quality and consistency of data which is critical in data-driven decision-making processes. Data is organized into hierarchies and presented in multi-dimensional formats, enabling better query performance and improved end-user access. This option is ideal for organizations with a mature data warehousing strategy and ongoing needs for complex analytics.
As the size and complexity of data grows, it can be challenging to scale the ADM to meet the changing needs of the organization. Adding new data sources or changing the structure of the data requires significant resources and time. In addition, as the number of users accessing the data mart increases, query performance can be impacted, leading to slower response times.
| Advantages | Disadvantages |
Fast query performance |
More work upfront |
More control over data quality and consistency |
Limited scalability |
Easy data accessibility for business users |
Potential data silos |
Cost-effective for specific data needs |
Can be complex to implement and maintain |
Ideal for complex analytics projects |
|
Data Lake – Advantages and Disadvantages
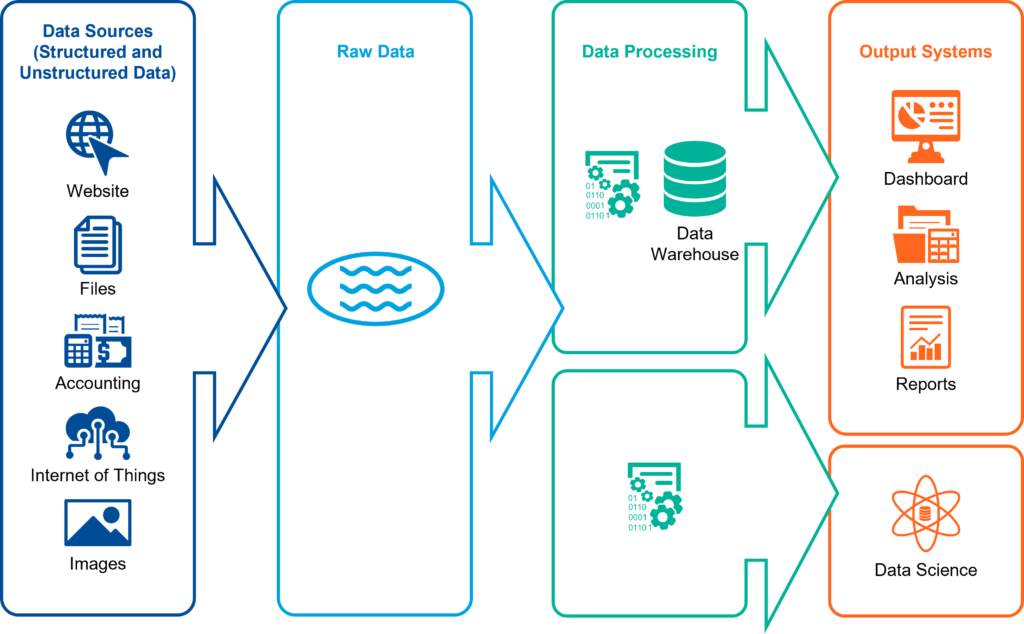
On the other hand, a Data Lake is more accommodating of unstructured data and stores it in raw form making the Data Lake approach a more flexible and cost-effective option. The Data Lake allows organizations to store data from multiple sources in their native formats without upfront transformation or restructuring requirements. Typically, Data Lakes are implemented using technologies/platforms like Hadoop or other big data technologies, providing an open but secure platform for storing and managing large volumes of data. Data Lakes enable the easy addition of new data sources and support agile analytics through their flexible schema-on-read design approach.
However, data quality and consistency can become issues, as data is ingested from diverse sources without immediate consideration of its contribution to broader business objectives. In a Data Lake, data quality is the responsibility of the reader of the data. As a result, data quality management for a Data Lake is decentralized versus an ADM where it’s more centralized. With a Data Lake you need a higher number of people who know how to make sure data is clean and ready for use. Whereas, with an ADM only a few people must know how to ensure data quality. So more organizational “trust” of a broader set of people is required in a Data Lake environment which may make data quality control more onerous.
If adequate data quality and data governance measures are not implemented, a Data Lake will eventually degenerate into a Data Swamp. Data in a Data Swamp is either inaccessible to intended users or difficult to manipulate, and—inevitably—analyze.
Assessing the quality of data is always a challenge, and this challenge is amplified when working with large volumes of data stored in a Data Lake. One of the common mistakes organizations make is using a “schema on read” approach to access data without understanding the context in which the data was generated. This can result in drawing erroneous conclusions and making incorrect decisions based on flawed data. For example, if an e-commerce company is analyzing sales data without considering seasonality or market trends, they could make poor decisions about inventory management or pricing.
To avoid these issues, it is important to understand the context in which data was generated and ensure that data is properly structured before analysis. Implementing data governance policies and practices can help to ensure the credibility of the data obtained from a Data Lake. By taking these steps, organizations can more confidently analyze the data in their Data Lakes and extract valuable insights that can drive business success.
| Advantages | Disadvantages |
Unlimited scalability |
Complexity of implementation |
Flexibility to store diverse data types |
Requires skilled resources for management |
Ability to handle large data volumes |
Potential data governance and security concerns |
Ideal for complex analytics projects |
Data quality and consistency may be challenging |
Ensure You Choose the Right Approach
Choosing the right approach for architecting an analytics-supporting data repository is an important decision that can impact your organization’s ability to leverage insights from its data effectively. While both the ADM and Data Lake approaches have their own advantages and disadvantages, the choice ultimately depends on your organization’s specific needs and priorities.
Tools like Alteryx Server/Designer, Talend Open Studio, KNIME Analytics Platform, or Azure Data Factory can help to automate the process of cleaning, transforming, and validating data before analysis, ensuring that data is of high quality and can be trusted. However, different data preparation tools connect ADMs versus Data Lakes. Some tools also connect to both, so knowing which tools work for a particular data storage solution may take some investigation. A careful analysis of the benefits, limitations, and potential impacts on cost, scalability, and performance is essential before committing to either approach.
ADM approaches are ideal for enterprises with substantial structured data sources and complex queries where data quality and consistency are crucial. Data Lakes are great for organizations that deal with diverse data from different sources and can benefit from agile analytics using a more flexible schema. In any case, it is necessary to remember that the implementation of a data repository to support your organization’s specific analytics requirements is a long-term investment, and it needs to be set up, managed, and maintained well to provide value over time.
A Final Thought
The reality is that data projects are never “done”, and the design of the analytical repository must support the future onboarding of new data assets or support the development of new analytical capabilities. Without the ability to grow and evolve, an analytical repository becomes less useful over time and eventually fades until it only delivers legacy reports that can’t be migrated to new platforms. One fundamental design premise for all data work that Optimus SBR delivers is extensibility. We design all analytical repositories with the premise that “things change” and new data or capabilities must be added. The architecture and the technology stack are designed to grow with the organization’s needs.
Optimus SBR’s Data Practice
Optimus SBR provides data advisory services customized to support the needs of public and private sector organizations. We offer an end-to-end solution, from data strategy and governance to data infrastructure, engineering, analytics, data science, visualization, insights, and training.
Contact Us to learn more about our Data practice and how we can help you on your data journey.

Optimus SBR Celebrates 6 Consecutive Wins as 2024 Best Workplaces™ in Professional Services
Our commitment to a people-first approach has been central to being recognized in 2024 for the sixth time as one of the Best Workplaces™ in Professional Services and the key to our overall success.

12 Best Practices to Increase Cross-Team Collaboration and Enhance Organizational Alignment
Enhancing cross-team collaboration drives innovation, optimizes resources, improves overall performance, and ensures every part of your organization works toward the same goals.

Enhancing Your Data Strategy for Success: The Power of Metadata
Metadata goes beyond just aiding in data retrieval. It ensures your data is secure, compliant and, most importantly, understood consistently by everyone in the organization.
Optimizing Language Translation Strategies: Beyond Compliance to Enhanced Operational Efficiency
The introduction of Quebec’s Bill 96 in Canada underscores the necessity for comprehensive translation strategies. Integrating machine translation technologies helps meet regulatory requirements while enhancing translation speed, cost efficiency, and operational effectiveness.

How to Manage Gen Z: 16 Strategies to Engage and Retain Young Talent
These practical strategies lead to a workplace that is better aligned with the values and expectations of Gen Z employees, ensuring that your efforts to attract and retain Gen Z talent are both successful and sustainable.

How to Measure the Success of Learning and Development: 12 Important Metrics to Evaluate
Quantifying the success of L&D training programs can be challenging. Learn about selecting and measuring the right metrics to determine whether your training efforts are truly making an impact.